Not because the feature is broken. Because a CSS class changed, or a button got a new ID, or someone rewrapped a form. The test knows nothing but "element not found."
Traditional automated tests are brittle by design. They record what the UI looked like at one moment in time and shatter the instant that moment passes.
I wanted something smarter.
What AgenticWebQA Actually Does
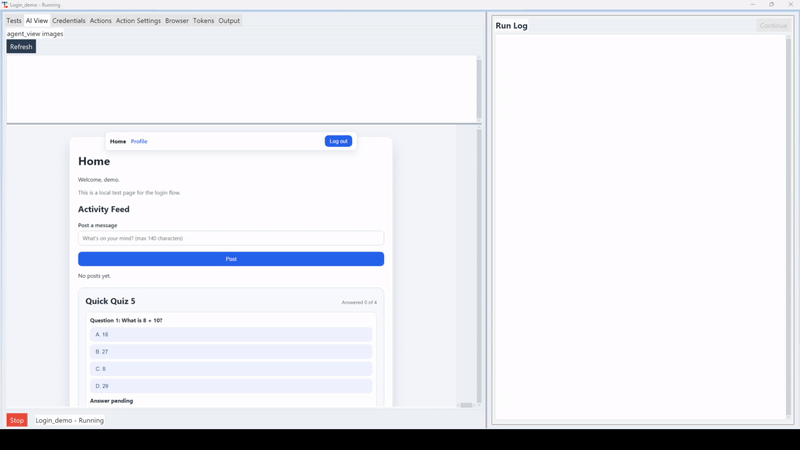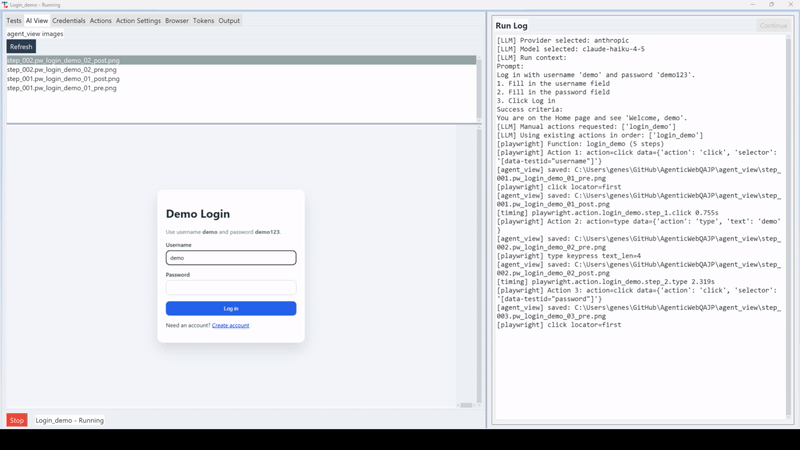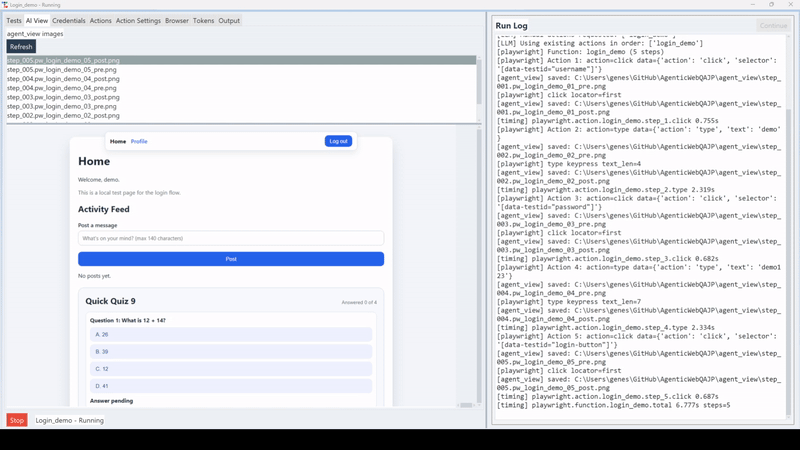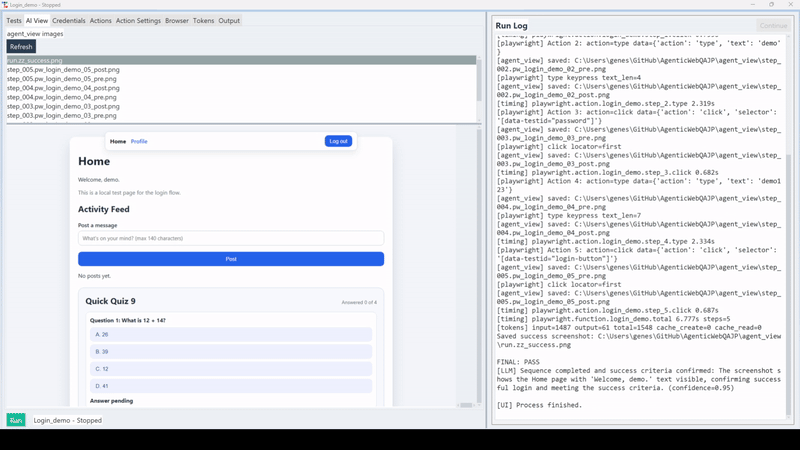
AgenticWebQA is an open-source browser automation agent that runs your web UI tests using a combination of Playwright and large language models. You describe what you want tested in plain English, and the agent figures out how to do it; clicking buttons, filling in forms, navigating between pages, using both DOM selectors and visual understanding of the screen.
The key word there is agent. This isn't record-and-playback. The LLM reads the page, reasons about what it sees, and decides what to do next.
Self-Healing That Actually Works
The self-healing in AgenticWebQA works differently from what most "auto-healing" products sell you. It doesn't silently patch broken selectors after the fact and call that intelligence. Instead, it runs in two phases:
Phase 1: Learn. The first time the agent runs a test, it explores the site using the LLM in full vision mode. As it navigates each step, clicking a login button, filling a username field, it records the DOM selectors and actions that worked as a named, reusable function.
Phase 2: Execute. On every subsequent run, the agent tries the reusable function first. Playwright executes it directly, with no model call needed. If a selector is gone because a developer changed something, the agent doesn't fail. It falls back to vision mode, figures out where the target is now, succeeds, and updates the test for next time.
The result is a test that doesn't fail on the first minor UI change it encounters. It adapts in the same run, passes, and keeps the learned knowledge updated. You fix the test by running it, not by hunting down broken locators.
Written in Plain English
Not everyone on a QA team is a developer. One of the explicit design goals here was that a less technical QA engineer should be able to write tests without knowing CSS selectors, XPath, or the DOM structure of the page being tested.
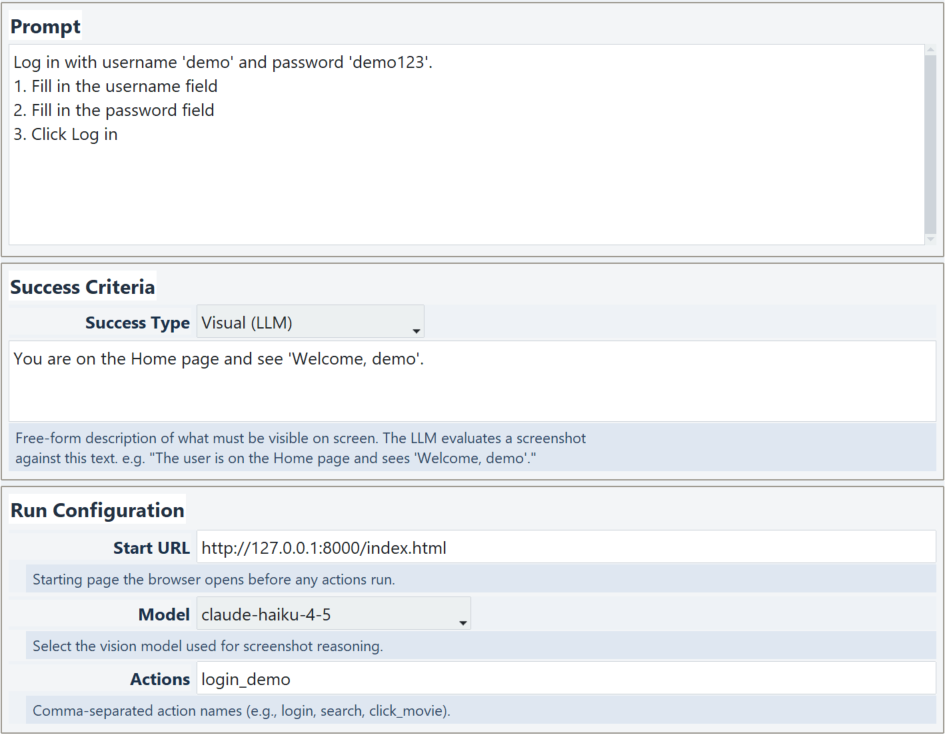
A test in AgenticWebQA looks like this:
Log in with username 'demo' and password 'demo123'.
1. Fill in the username field
2. Fill in the password field
3. Click Log inFirst-Class CLI for CI/CD
Success criteria: You are on the Home page and see 'Welcome, demo'.That's it. No imports, no selectors, no waiting for elements. You describe the task the way you'd describe it to a human, and the agent works out the rest.
The GUI makes this even more accessible. It's a simple launcher where you type your prompt, pick your model, hit Run, and watch the browser do its thing. For teams that live in CI pipelines, the same test runs identically from the command line.
First-Class CLI for CI/CD
The GUI is for authoring and exploration. The CLI is for automation.
Every test in AgenticWebQA can be invoked as a standard shell command, which means it drops into any CI/CD pipeline that can run Python; GitHub Actions, Jenkins, CircleCI, local pre-commit hooks. You pass in your prompt, success criteria, and start URL as flags and you get a clean exit code back.
Credentials can stay out of the command line entirely through environment variables (WEBQA_USERNAME, WEBQA_PASSWORD) so secrets don't leak into logs. The AI is also able to variablize parts of your prompt including tools like string functions you can insert that will modify the prompt based on an AgenticWebQA string function you create. These are for things like using current time/date, generating random strings, or anything else you can code logic for that results in a string being output.
The Login test from the previous section becomes a single shell command. Using the Visual (LLM) success type — matching the GUI shown in the screenshots above — the LLM checks the page visually to determine if the success criteria is met:
agenticwebqa run \
--prompt "Log in with username 'demo' and password 'demo123'. \
1. Fill in the username field \
2. Fill in the password field \
3. Click Log in" \
--visual-llm-success "You are on the Home page and see 'Welcome, demo'" \
--url https://example.com/login \
--model claude-sonnet-4-20250514If you want to skip the LLM call that Visual LLM success type requires you can go with something like Selector Present success type, and just pass in a CSS selector to check for instead:
agenticwebqa run \
--prompt "Log in with username 'demo' and password 'demo123'. \
1. Fill in the username field \
2. Fill in the password field \
3. Click Log in" \
--selector-present-success ".welcome-banner" \
--url https://example.com/login \
--model claude-sonnet-4-20250514Dirt Cheap to Run
This is where things get interesting compared to the commercial auto-healing test platforms.
AgenticWebQA is designed to be aggressive about cost. A typical test run with the recommended flags costs around $0.01 per step. A full login-to-profile-edit flow might run 8–12 steps on a good day, roughly ten to fifteen cents per test execution. That is just for the initial training. Once that runs and outputs a test script you're looking at potentially 0 steps per test going forward.
That's not a ballpark. It's the actual output of the cost controls built into the agent: aggressive message pruning, stripping screenshot history to only the most recent frame, capped token budgets per response, and optional screenshot downscaling. You can tune all of it. You can also run cheaper models for simpler tests and reserve the heavy models for difficult pages or initial learning runs.
Compare that to SaaS auto-healing platforms that charge per test run, per seat, or per "healing event", often in the hundreds or even tens of thousands of dollars a month for their simplest configurations. AgenticWebQA has no subscription, no per-seat pricing, no vendor controlling what you can run or how many tests you can have.
No Lock-In
AgenticWebQA is a Python project. It runs anywhere Python runs; your laptop, a Linux VM, a GitHub Actions runner, a cheap cloud instance. You own the code. You own the learned actions. You own the hints file.
The learned selector library is a plain JSON file you can read, edit, commit to source control, and share across your team. The reusable action functions are also plain JSON. Nothing is locked in a proprietary format or stored on someone else's server.
If you want to run it on a cheap VPS, you can. If you want to run it on your local machine during development and push results to CI, you can. You're not buying into a service contract. You're running a tool.
Supports Multiple LLMs
Different tests have different needs, and different teams have different API relationships. AgenticWebQA supports both OpenAI and Anthropic model families out of the box.
You pick the model per test. A registration flow that needs to handle dynamic form behavior might run on Opus. A smoke test checking that the nav links render correctly can run on Haiku at a fraction of the cost. The model is just a CLI flag or a dropdown selection, so you're not locked into one provider's pricing or capability ceiling.
Why I Built This
I'd been watching the "AI-powered testing" space fill up with SaaS products making big promises about self-healing tests, and most of them were either expensive, opaque about how the healing actually worked, or both. The underlying technology was all available to anyone with an API key; vision models, browser automation, LLM reasoning.
So I built the direct version: a small, transparent, self-hostable agent that does the actual work, costs almost nothing to run, and doesn't ask you to sign a contract to use it.
AgenticWebQA is still early. There's more to build; better reporting, broader action coverage, richer test orchestration. But the core loop works: describe a test in plain English, let the agent learn the site, and get tests that adapt instead of break.
If you're tired of maintaining brittle test suites, give it a look on GitHub or watch a demo on YouTube.